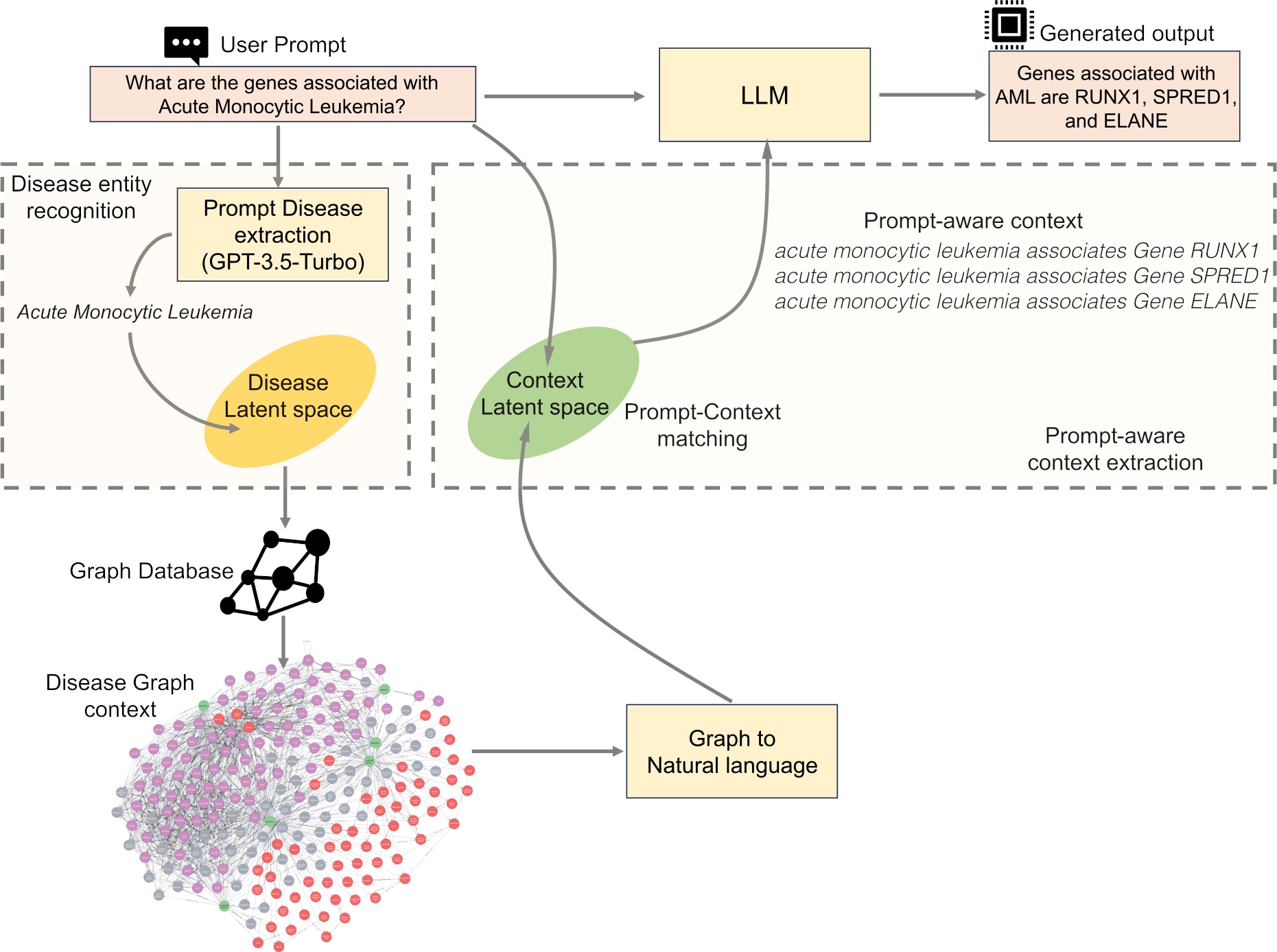
We just released a preprint where Dr. Soman proposes a task agnostic framework that combines the explicit knowledge of a Knowledge Graph (KG) with the implicit knowledge of a Large Language Model (LLM).
In this paper, we utilize a massive biomedical KG called SPOKE as the provider for the biomedical context. SPOKE has incorporated over 40 biomedical knowledge repositories from diverse domains, each focusing on biomedical concept like genes, proteins, drugs, compounds, diseases, and their established connections. SPOKE consists of more than 27 million nodes of 21 different types and 53 million edges of 55 types [Ref].
The main feature of KG-RAG is that it extracts "prompt-aware context" from SPOKE KG, which is defined as:
the minimal context sufficient enough to respond to the user prompt.
Hence, this framework empowers a general-purpose LLM by incorporating an optimized domain-specific 'prompt-aware context' from a biomedical KG.
Try it yourself! We just released it on Github.
We also want to thank Anthony Alcaraz for writing about our work here!
Support Our Work
We are committed to open science, and we make all of our work available to the scientific community and those interested in new discoveries in any biomedical area.